Amazon Prime has moved away from serverless – should you?

Max Hayward, Ten10 Principal DevOps Consultant, breaks down why Amazon is shifting back to monolith and whether you should do the same
Amazon recently shook the cloud architecture world by deciding to move its Prime service away from serverless and back to a monolithic architecture. This may seem drastic (and it probably is) but they have clearly given it much thought and outlined the decision in a blog post. Let’s explore the reasons for this and consider whether or not it will signal a wider industry shift away from serverless architecture.
The context
First, a very brief introduction to serverless. If modern cloud architecture was broken down into three historical events, it would be as follows:
- Monolith: The entire application is delivered via a single deployment and is available at one single endpoint, with all logic existing in the same place. Compute capacity is usually a single location or a small number of servers, vertically scalable, and billed per server.
- Microservices: The application is split into many services, each with its own responsibility. The services interact with each other to complete business logic. Each service is deployed to, and lives, separately. The compute capacity is horizontally scalable, but usually still billed individually per server.
- Serverless (aka Function As A Service): The application is broken down into individual functions, each uniquely deployable. Functions generally interact as part of an asynchronous workflow.
So, serverless seems to be the most scalable offering. The word ‘serverless’ is a bit misleading, as there are still the same servers running in the background. It’s just the responsibility of server management (thus scalability management) is offloaded to the cloud provider, therefore the billing model has to change. It’s certainly the most recent architecture innovation and it brings many benefits to organisations that use it, but as with any new technology or framework, many early adopters may have done so purely due to it being the “new kid on the block”.
Amazon Prime
The serverless use case was focused on a monitoring service within the application. Every video that is watched by a user goes through a process that monitors for errors in the video and fixes them accordingly. This was managed by a team dedicated to ensuring video quality (the Video Quality Analysis team).
The monitoring tool consisted of distributed serverless components, including AWS Lambda and AWS Step Functions (a serverless workflow orchestration tool). It was built in this way to allow each component in the service to scale independently of the rest.
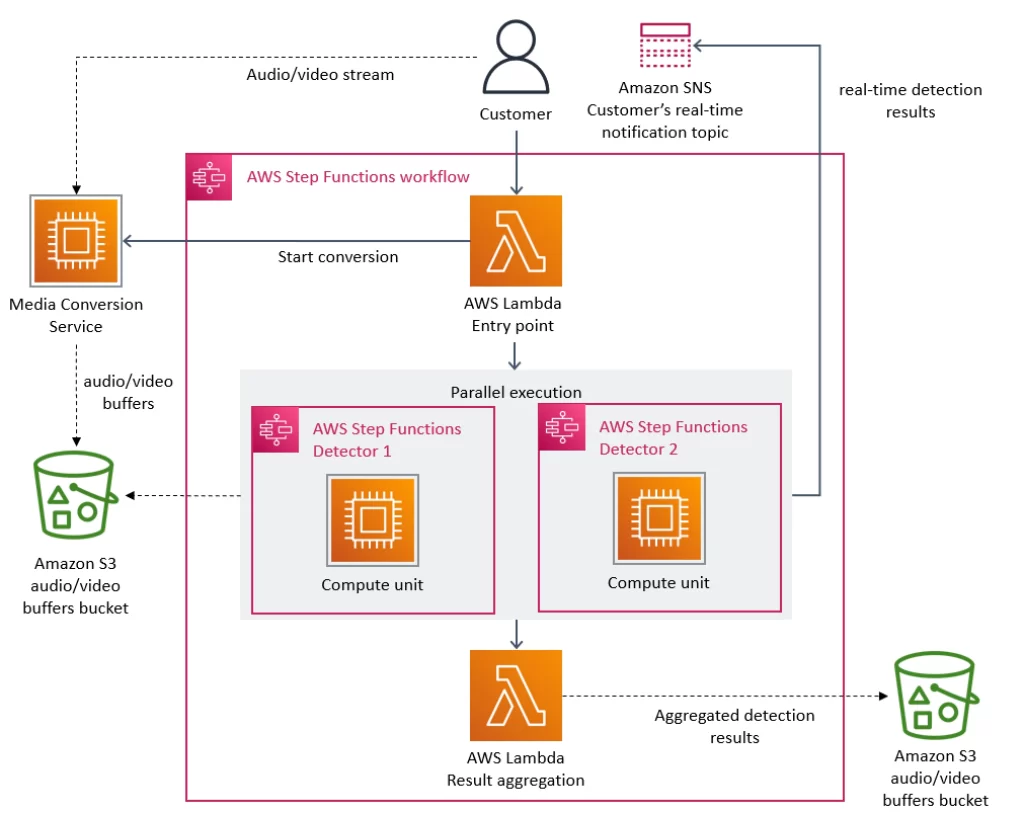
Source: Amazon
The problem
The primary problem with the above solution, in practice, is cost. Specifically the Step Functions, which charge per state transition. The monitoring service performed multiple state transitions for every second of the stream. Another large cost was related to the transmission of data between the different components. Due to the distributed nature of the service, data transfer inherently will cost more.
As mentioned earlier, the billing model to the user must change due to the responsibility abstractions of serverless. It’s important to note that previous cost estimation models will need adapting to serverless architecture. It’s definitely possible to avoid unexpected spikes in cost due to underestimating scalability – but it’s harder with serverless.
The solution: back to monolith
So, Amazon decided to move it all back to a monolith. The distributed approach wasn’t bringing them the benefits they expected, so they packed everything into a single process. Since the data was being used by the same process, they didn’t need the centralised storage (S3 Buckets) and everything could live in application memory. Using Amazon ECS (Elastic Container Service) backed by EC2 completely removed the need for any Step Functions or Lambda Functions for compute capacity.
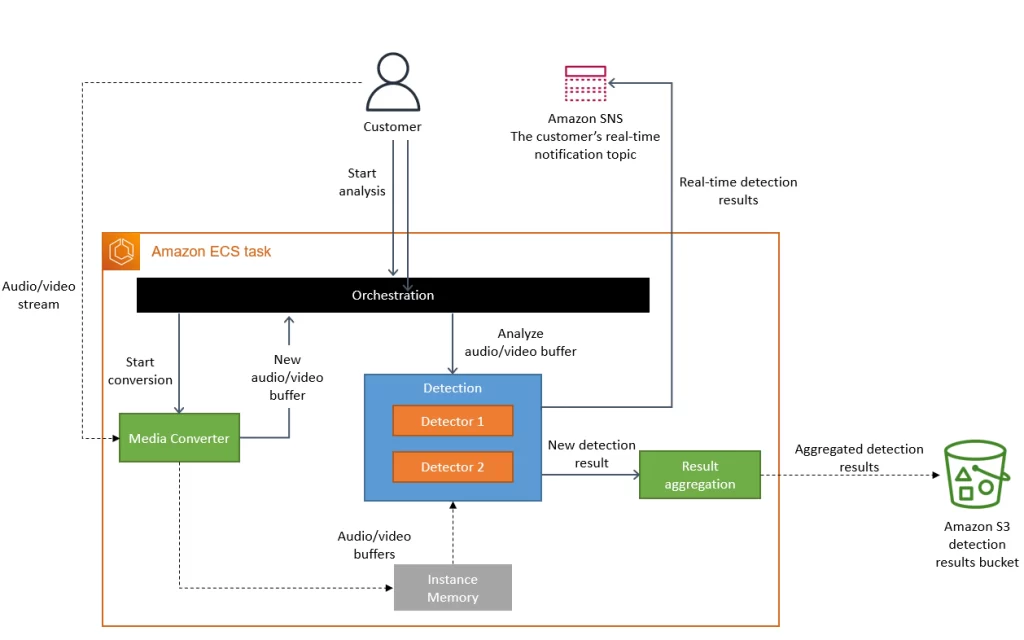
Source: Amazon
The impact
The immediate impact of this change to Amazon is bittersweet. On one hand, Amazon Prime has made some great cost savings (over 90% reduction). On the other hand, AWS (still Amazon) has lost a great revenue stream.
As far as the wider impact of this change on the cloud computing industry, the jury is still out. There has certainly been discussion in recent years about the pitfalls of serverless, but this is probably the highest profile publicised shift of a major service away from the architecture.
What should you do?
There is no hard and fast rule here. Each application or service is an entirely different use case, and whichever architecture is right for you will be dependent on multiple factors. You certainly shouldn’t ignore serverless on the basis of this AWS post. Ultimately, it’s about finding the right balance based on what your priorities are.
Ask yourself the following questions:
- Is it a new service? Perhaps starting a proof-of-concept as a monolith will reduce the architecture overheads. Planning out a serverless architecture can be a complex and time-consuming process.
- Is the workflow synchronous or asynchronous?
- How resilient does your application need to be? Do you need each component to be independently fault tolerant?
- How complex do you expect the architecture to be?
- How consistent (or inconsistent) do you expect the activity on the application to be? This is one of the hardest questions to answer as we cannot see into the future. But generally, if your application is going to experience extremely quiet periods, then the scalability benefits of serverless may be of value to you.
Above all, whether or not you decide to go down the serverless route, the lesson we should all learn from Amazon is to fully understand the cost implications of your application, in serverless, and at scale.